【scikit-learn基础】--『监督学习』之 层次聚类
导读:层次聚类 算法是机器学习中常用的一种无监督学习算法,它用于将数据分为多个类别或层次。.该方法在计算机科学、生物学、社会学等多个领域都有广泛应用。.层次聚类 算法的历史可以追溯到上世纪60年代,当时它主要被用于社会科学中。.随着计算机技术的发展,这种方法在90年代得到了更为广泛的应
层次聚类 算法是机器学习中常用的一种无监督学习算法,它用于将数据分为多个类别或层次。
该方法在计算机科学、生物学、社会学等多个领域都有广泛应用。
层次聚类 算法的历史可以追溯到上世纪60年代,当时它主要被用于社会科学中。
随着计算机技术的发展,这种方法在90年代得到了更为广泛的应用。
1. 算法概述
层次聚类 的基本原理是创建一个层次的聚类,通过不断地合并或分裂已存在的聚类来实现。
它分为两种策略:
- 凝聚策略 :初始时将每个点视为一个簇,然后逐渐合并相近的簇
- 分裂策略 :开始时将所有点视为一个簇,然后逐渐分裂
在scikit-learn中,层次聚类 的策略有4种 :
ward:默认策略,也就是最小方差法。它倾向于合并那些使得合并后的簇内部方差最小的两个簇complete:计算两个簇之间的距离时,考虑两个簇中距离最远的两个样本之间的距离average:计算两个簇之间的距离时,考虑两个簇中所有样本之间距离的平均值single:计算两个簇之间的距离时,考虑两个簇中距离最近的两个样本之间的距离
2. 创建样本数据
下面创建月牙形状数据来看看层次聚类的各个策略之间的比较。
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
ax = plt.subplot()
X, y = make_moons(noise=0.05, n_samples=1000)
ax.scatter(X[:, 0], X[:, 1], marker="o", c=y, s=25, cmap=plt.cm.prism)
plt.show()
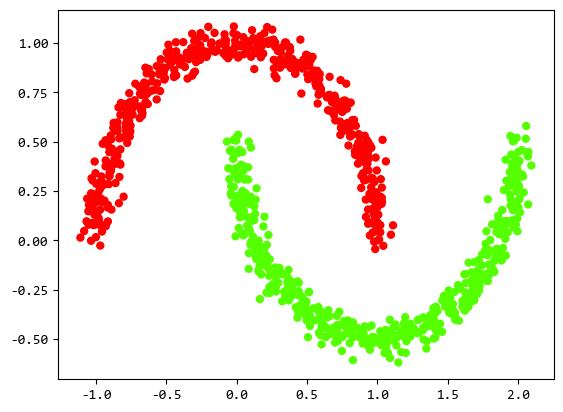
关于各种样本数据的生成,可以参考:TODO
3. 模型训练
用四种不同的策略来训练上面月牙形状的样本数据。
from sklearn.cluster import AgglomerativeClustering
# 定义
regs = [
AgglomerativeClustering(linkage="ward"),
AgglomerativeClustering(linkage="complete"),
AgglomerativeClustering(linkage="single"),
AgglomerativeClustering(linkage="average"),
]
# 训练模型
for reg in regs:
reg.fit(X, y)
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_size_inches((10, 8))
# 绘制聚类之后的结果
axes[0][0].scatter(
X[:, 0], X[:, 1], marker="o", c=regs[0].labels_, s=25, cmap=plt.cm.prism
)
axes[0][0].set_title("ward 策略")
axes[0][1].scatter(
X[:, 0], X[:, 1], marker="o", c=regs[1].labels_, s=25, cmap=plt.cm.prism
)
axes[0][1].set_title("complete 策略")
axes[1][0].scatter(
X[:, 0], X[:, 1], marker="o", c=regs[2].labels_, s=25, cmap=plt.cm.prism
)
axes[1][0].set_title("single 策略")
axes[1][1].scatter(
X[:, 0], X[:, 1], marker="o", c=regs[3].labels_, s=25, cmap=plt.cm.prism
)
axes[1][1].set_title("average 策略")
plt.show()
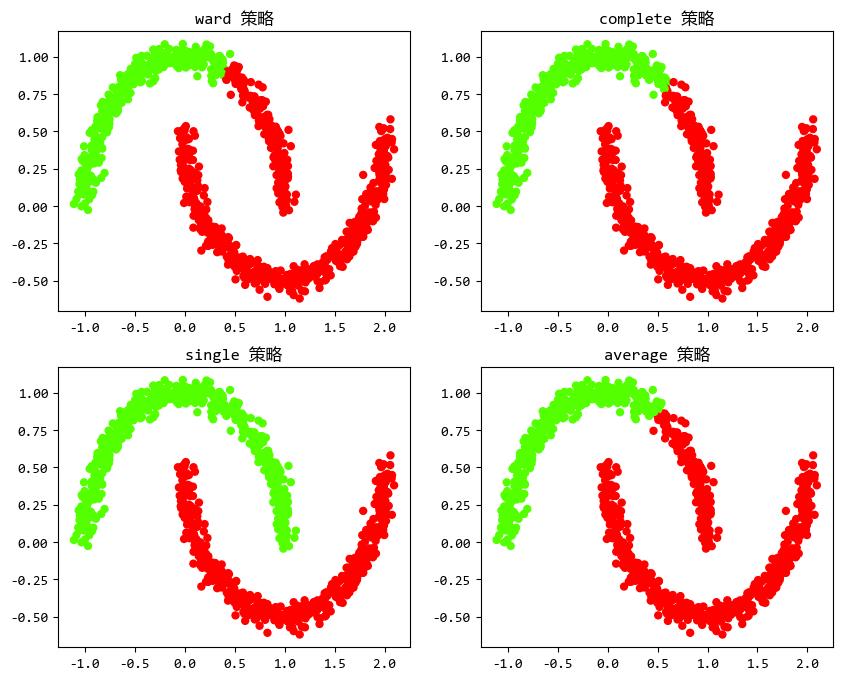
从结果可以看出,single策略 效果最好,它聚类的结果与原始数据的分类情况最为接近。
不过,这并不能说明single策略 由于其它策略,只能说明single策略 最适合上面的样本数据。
4. 总结
层次聚类 在许多场景中都得到了应用,例如图像分割、文档聚类、生物信息学中的基因聚类等。
它特别适合那些需要多层次结构的应用。
层次聚类 的最大优势 在于它提供了一种层次结构的聚类,这对于许多应用来说是非常自然 的,它能够展示数据在不同粒度下的聚类结果。
但它也存在一些缺点 。
首先,它的计算复杂度 相对较高,特别是当数据量很大时;
其次,一旦做出合并或分裂的决策,就不能撤销,这可能导致错误的累积 。
此外,确定何时停止 合并或分裂也是一个挑战。
上一篇:What is FFT? FFT
下一篇:umich cv-2-2

















