聊聊分布式 SQL 数据库Doris(一)
导读:MPP.MPP:Massively Parallel Processing, 即大规模并行处理..一般用来指多个SQL数据库节点搭建的数据仓库系统. 执行查询的时候, 查询可以分散到多个SQL数据库节点上执行, 然后汇总返回给用户..Doris.Doris 作为一款开源的 MPP
MPP
MPP:Massively Parallel Processing, 即大规模并行处理.
一般用来指多个SQL数据库节点搭建的数据仓库系统. 执行查询的时候, 查询可以分散到多个SQL数据库节点上执行, 然后汇总返回给用户.
Doris
Doris 作为一款开源的 MPP 架构 OLAP 高性能、实时的分析型数据库,能够运行在绝大多数主流的商用服务器上。
架构组成
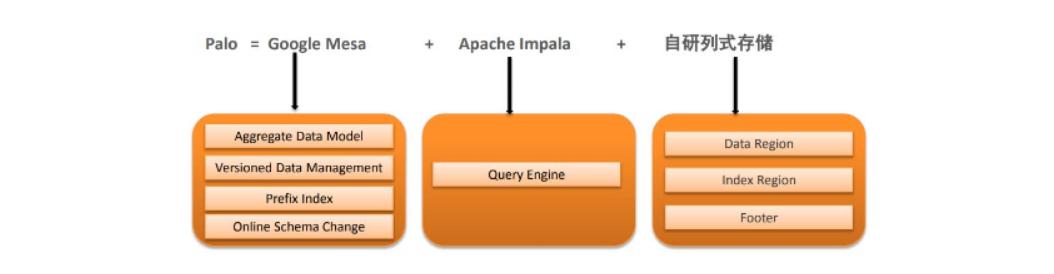
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。
Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。
Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎。
自研列式存储:存储层对存储数据的管理通过storage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录下存放具体的tablet,按照tablet_id命名子目录。因此选择了这三种技术的组合。
使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。
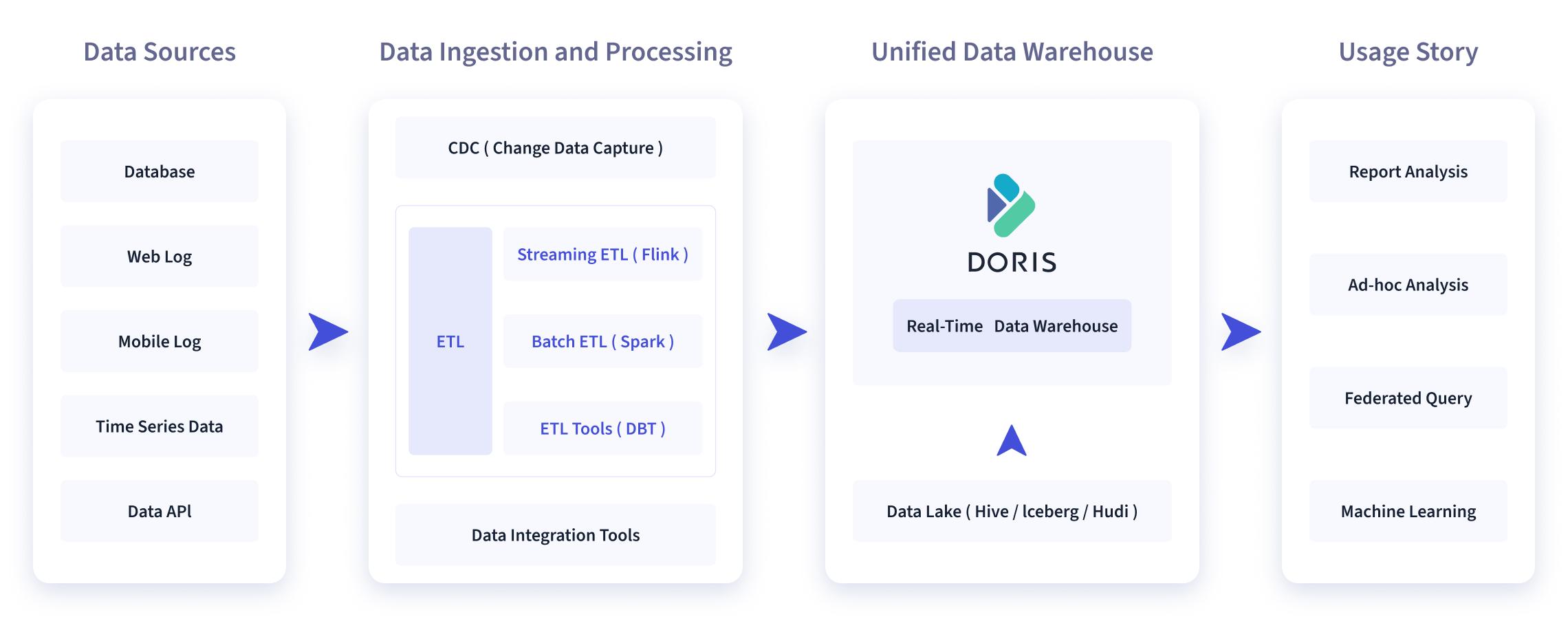
报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
架构概述
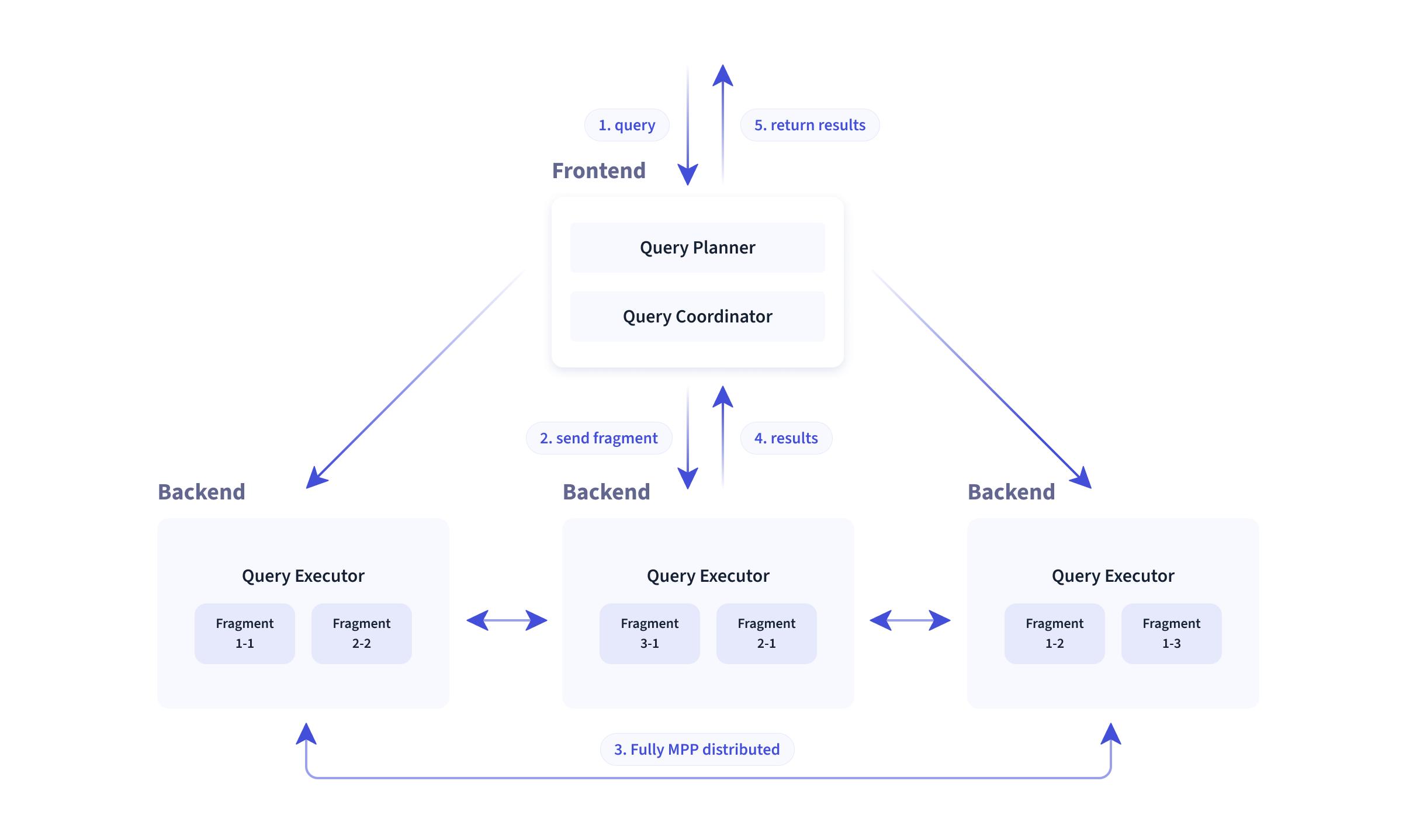
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程
- Frontend(FE), 主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理、生成查询计划相关工作。
- Backend(BE), 主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议 来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。
FE主要分为三个角色:Leader、Follower、Observer及其作用:
- leader, follower: 在Leader宕机之后,Follower节点能够迅速代替Leader的工作,能够实现实时恢复元数据,从而保证对Doris集群不造成任何影响;leader负责数据的写入.
- observer: 用来拓展查询节点, 仅从leader节点同步元数据, Observer只参与读取,不参与写入
类似Zookeeper中的节点角色及其职责。
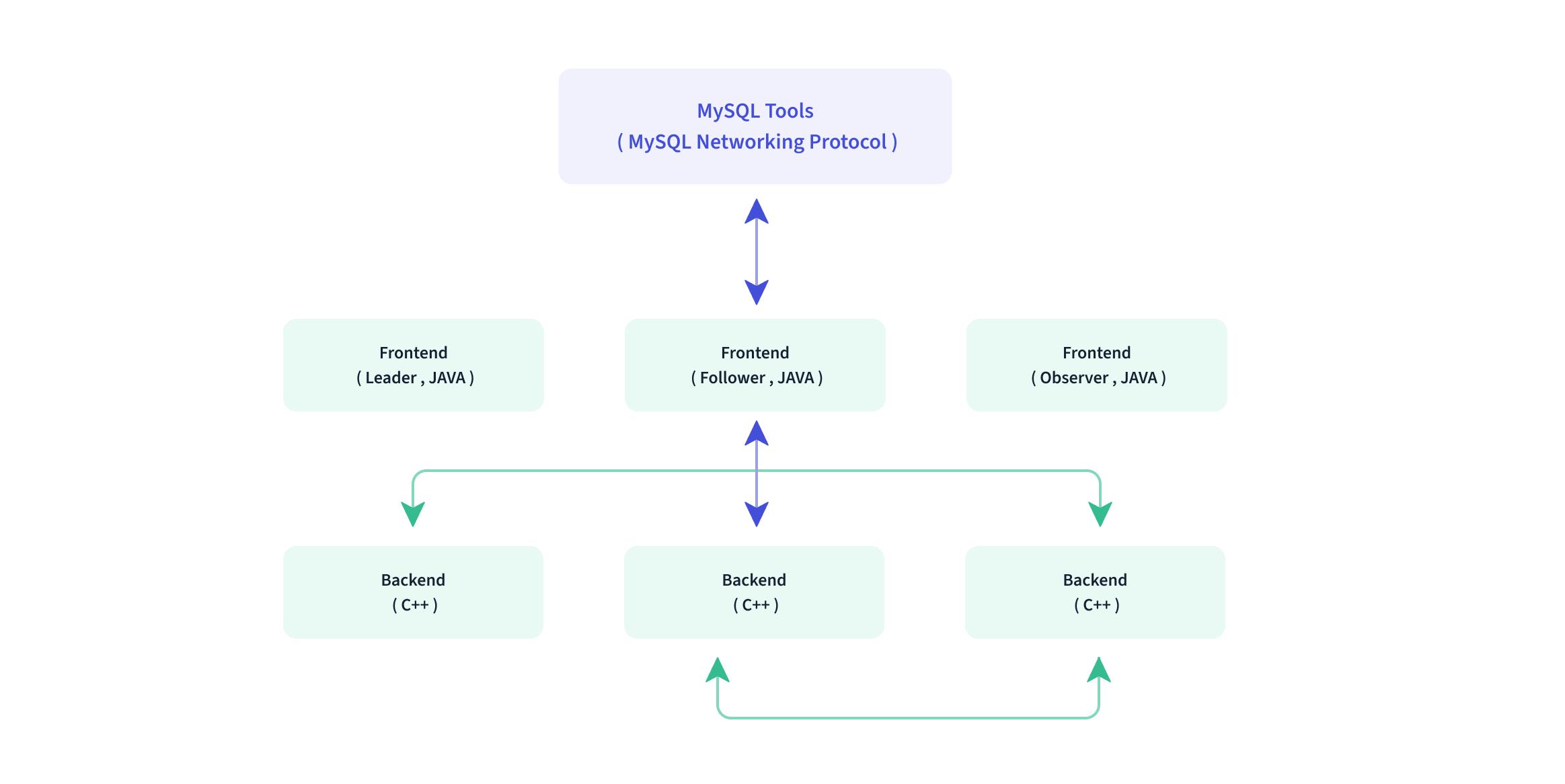
具体的来说:
Backend(BE)节点:
- BE 节点是 Apache Doris 中的数据存储和计算节点。每个 BE 节点负责存储和管理分配给它的表的数据。
- 数据以分区为单位存储在 BE 节点上,而分区是表的逻辑组织单位,用于提高查询性能和管理数据。
- BE 节点还执行查询计划,进行数据的读写、计算等操作,是实际进行数据处理的节点。
Frontend(FE)节点:
- FE 节点是 Doris 中的前端节点,负责接收用户请求、解析查询语句、生成查询计划等前端任务。
- FE 节点并不存储实际的数据,而是将用户请求翻译为查询计划,并将查询计划发送给 BE 节点执行。
- FE 节点还负责元数据的管理,包括表的定义、分区信息、索引等。
在使用接口 方面,Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Doris,并支持与 BI 工具的无缝对接。Doris 当前支持多种主流的 BI 产品,包括不限于 SmartBI、DataEase、FineBI、Tableau、Power BI、SuperSet 等,只要支持 MySQL 协议的 BI 工具,Doris 就可以作为数据源提供查询支持。
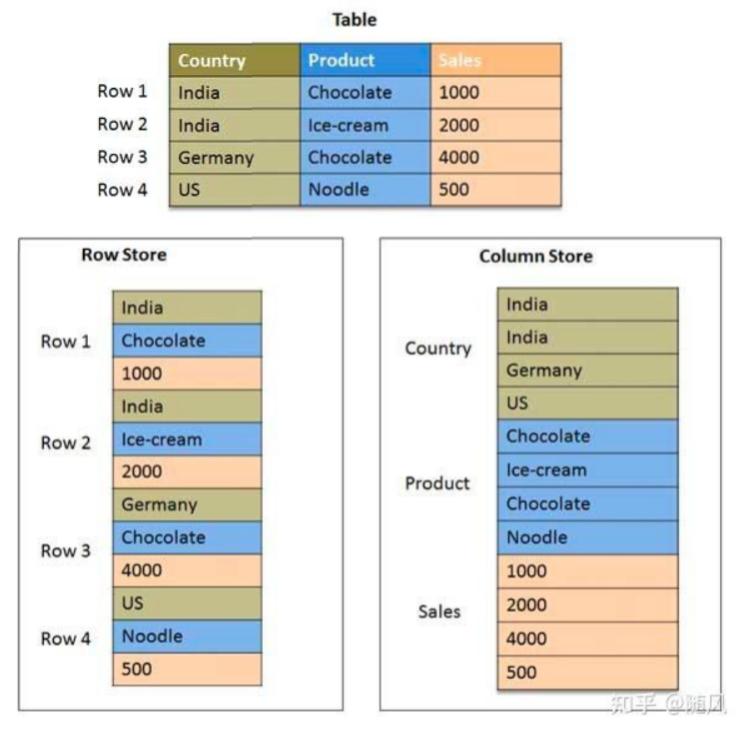
在存储引擎 方面,Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
列式存储(column-based) 是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。简单来说两者的区别就是如何组织表:
Doris 也支持比较丰富的索引结构,来减少数据的扫描:
- Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景
- Min/Max :有效过滤数值类型的等值和范围查询
- Bloom Filter :对高基数列的等值过滤裁剪非常有效
- Invert Index :能够对任意字段实现快速检索
在存储模型方面,Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- Aggregate Key 模型:相同 Key 的 Value 列合并,通过提前聚合大幅提升性能
- Unique Key 模型:Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新
- Duplicate Key 模型:明细数据模型,满足事实表的明细存储
Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列, 可以认为只是 “排序列”,并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 “排序列” 和 “唯一标识列”,是真正意义上的“ key 列”。索引的创建与key列是直接相关的。
Doris 也支持强一致的物化视图,物化视图的更新和选择都在系统内自动进行,不需要用户手动选择,从而大幅减少了物化视图维护的代价。
在查询引擎方面,Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。
参考:
Doris (Incubating) 原理与实践
上一篇:ASR项目实战-后处理
下一篇:使用redis pipeline








![[Lua][Love] "图块集与地图" 加载显示功能 TileMap](/img/news/1710877327223.jpg)














